본 글은 공부를 위해 작성된 글입니다. 설명이 많이 부족하거나 미흡할 수 있습니다.
학습 대상
- XML
- DOM
- 정규표현식
- Tokenizer, Lexer, Parser
XML
XML은 EXtensible Markup Language의 약자로, HTML과 똑같이 문자 기반의 마크업 언어입니다. 다만 HTML과는 만들어진 목적이 다릅니다. HTML은 데이터의 구조를 보여주는데 초점이 맞춰져 있다면, XML은 데이터를 저장하고 전달하기 위해 디자인 된 언어입니다.
또한 XML 태그는 HTML 태그처럼 미리 정의되어 있지 않고, 사용자가 직접 정의할 수 있습니다.
Markup Language란?
Markup Language는
태그등을 이용하여 문서나데이터의 구조를 명기하는 언어의 한 가지입니다. 일반적으로 데이터를 기술하는 정도로만 사용되기에 프로그래밍 언어와는 구별됩니다.
DOM
DOM이란?
DOM은 Document Object Model의 약자입니다. 번역을 하면 문서 객체 모델이라 하고, 여기서 문서 객체란이나와 같은 html문서의 태그들을 프로그래밍 언어가 이용할 수 있는 객체(Object)로 만들면 그것을 문서 객체라고 합니다.
Model은 다양한 의미가 있고, 여기서는 문서 객체를 인식하는 방식이라고 해석할 수 있습니다.
즉 DOM은 넓은 의미로 HTML을 인식하는 방식을 의미하고, 좁은 의미로 문서 객체와 관련된 객체의 집합을 의미할 수도 있습니다.
DOM의 구조

DOM은 tree형식의 자료구조를 가지고 있습니다.
정규표현식
정규표현식이란?
정규표현식의 사전적인 의미로는 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어입니다. 주로 Programming Language나 TextEditor등 에서 문자열의 검색과 치환을 위한 용도로 쓰이고 있습니다. 입력한 문자열에서 특정한 조건을 표현할 경우 일반적인 조건문으로는 다소 복잡할 수도 있지만, 정규표현식을 이용하면 매우 간단하게 표현 할 수 있습니다.
정규표현식이 유용하게 사용될 때
- 각각 다른 포멧으로 저장된 엄청나게 많은 전화번호 데이터를 추출해야 할 때
- 사용자가 입력한 이메일, 휴대폰 번호, IP 주소 등이 올바른지 검증하고 싶을 때
- 코드에서 특정 변수의 이름을 치환하고 싶지만, 해당 변수의 이름을 포함하고 있는 함수는 제외하고 싶을 때
- 특정 조건과 위치에 따라서 문자열에 포함된 공백이나 특수문자를 제거하고 싶을 때
정규표현식 표현방법
정규표현식에서 사용하는 기호를 Meta 문자라고 합니다. Meta 문자는 표현식 내부에서 특정한 의미를 갖는 문자를 말합니다.
문자클래스'[]'
문자 클래스는 그 내부에 해당하는 문자열의 범위 중 한 문자만 선택한다는 의미이며, 문자 클래스 내부에서는 Meta문자를 사용할 수 없거나 의미가다르게 사용됩니다.


(이미지 출처 : https://www.nextree.co.kr/p4327/)
Tokenizer, Lexer, Parser
컴파일러란?
컴파일러는 소스코드를 기계어로 바꿔주는 역할을 합니다.
컴파일의 과정은 구문 분석 -> 코드 생성 -> 링킹의 과정을 거칩니다.
여기서 구문 분석은 Tokenizer, Lexer, Parser 3 단계로 나누어질 수 있습니다.
Tokenizer
어떤 대상의 의미있는 요소들을 토큰으로 쪼개는 역할
여기서 토큰이란, "어휘 분석의 단위"를 의미하는 컴퓨터 용어입니다. 이 단위는 단어나 단어구, 문자열 등 보통 의미있는 단위로 정합니다.
Lexer
Tokenizer에 쪼갠 토큰의 의미를 분석하는 역할
Tokenizer + Lexer의 두 가지 역할을 합해 Lexcial Analyze라고 합니다. Lexical Analye는 의미 있는 조각을 검출하여 토큰을 생성하는 것을 의미합니다.
토큰 단위로 키워드, 속성들을 정의하고 그 데이터를 Parser에게 넘겨줍니다.
Parser
Lexical analize되어 tokenize된 데이터를 가지고, 구조적으로 나타낸다.
그리고 데이터를 구조적으로 바꾸는 과정에서, 데이터가 올바른지 검증하는 역할도 수행한다.
HTML 문서의 Tokenizer -> Lexer -> Parser의 간단한 예시 (Java 데이터 타입 기준)
입력값
String : "<HTML lang=\"ko\"><BODY><P>BOOST<IMG SRC=\"codesquad.kr\"></IMG><BR/></P></BODY></HTML>"
토크나이저 결과
ArrayList<String> : [ "<HTML lang=\"ko\">", "<BODY>", "<P>", "BOOST", "<IMG SRC=\"codesquad.kr\">", "</IMG>", "<BR/>", "</P>", "</BODY>" , "</HTML>"]
렉서 결과
ArrayList<Node> :
[
{Tag : HTML, Attributes : [lang : "ko"], Childs : BODY},
{Tag : BODY, Childs : P},
{Tag : P, Childs : TEXT, IMG, BR},
{Tag : TEXT, Attributes : [lang : "BOOST"]},
{Tag : IMG, Attributes : [SRC : "codesquad.kr"]},
{Tag : CLOSING_IMG},
{Tag : BR},
{Tag : CLOSING_P},
{Tag : CLOSING_BODY},
{Tag : CLOSING_HTML},
]
파서 결과
{
element : HTML
attributes : [ { name : lang , value : ko } ]
child : [
{
element : BODY
child : [
{
element : P
child : [
{
element : TEXT
attributes : [ { name : TEXT , value : BOOST } ]
}
{
element : IMG
attributes : [ { name : SRC , value : codesquad.kr } ]
}
{
element : BR
}
]
}
]
}
]
}
(출처 : https://gobae.tistory.com/94)
기능요구사항
- HTML5, PLIST 같은 XML 데이터를 분석해서 요소별로 분리하는 DOM Parser를 구현한다.
프로그래밍 요구사항
- 기존에 구현된 XML 분석을 도와주는 xmldom 나 유사한 라이브러리와 node 모듈을 사용할 수 없으며, 이와 유사한 파싱을 처리해주는 외부 라이브러리를 모두 사용할 수 없다.
- 정규표현식은 token을 추출하고 분석하기 위한 용도로 사용할 수 있다.
- 전체 문자열 분석을 위해서 단계별로 역활을 나눠서 처리한다.
- tokenizer, lexer, parser를 처리하는 메서드를 각각 만든다.
- 함수가 길어지거나 너무 많은 역할을 하지않도록 하위 함수로 나눈다.
- 태그 중첩을 처리하기 위해서는 Stack 동작을 배열을 활용해서 직접 구현해야 한다.
- 만약 태그가 제대로 닫히지 않으면 stringify() 결과는 "올바른 XML 형식이 아닙니다."를 리턴한다.
자바로 구문 분석 코드 만들어보기
전체 소스 및 테스트 코드는 Gist에 저장되어 있습니다.
Tokenizer 구현

public class Tokenizer {
private static final Pattern TOKEN =
Pattern.compile("<[^><]+>|[^><]+");
public ArrayList<String> tokenize(String input) {
ArrayList<String> tokens = new ArrayList<>();
Matcher matcher = TOKEN.matcher(input);
while(matcher.find()) {
tokens.add(matcher.group());
}
return tokens;
}
}
Lexer 구현
1. 태그를 입력 받아 노드(Token) 만들기

public class NodeFactory {
/* 정규 표현식 생략 */
/* 생성자 생략 */
public ArrayList<Node> makeNodeArray(ArrayList<String> tags) {
ArrayList<Node> nodeArrayList = new ArrayList<>();
for (int i = 0; i < tags.size(); i++) {
nodeArrayList.add(makeNode(tags.get(i)));
}
return nodeArrayList;
}
public Node makeNode(String tag) {
Matcher matcher = CHECH_CRAMPS.matcher(tag);
if(matcher.find()) {
return makeTagNode(tag);
}
return makeTextNode(tag);
}
private Node makeTextNode(String tag) {
return new Node(Tag.TEXT, new Attribute(AttributeKey.TEXT,tag));
}
private Node makeTagNode(String tag) {
if (getTokenNum(tag) > 1) {
return makeTagWithAttNode(tag);
}
return makeTagWithoutAttNode(tag);
}
private Node makeTagWithAttNode (String tag) {
Matcher tokens = CHECH_ATT.matcher(tag);
Deque<String> tokenQue = convertTokenQue(tokens);
Tag tagName = strToTag(tokenQue.pop());
ArrayList<Attribute> attributes = getAttributeArray(tokenQue);
return new Node(tagName, attributes);
}
private Node makeTagWithoutAttNode (String tag) {
Matcher tagName = TAG_NAME.matcher(tag);
if (tagName.find()) {
return new Node(strToTag(tagName.group()));
}
System.out.println("예상치 못한 에러가 발생했습니다.");
return null;
}
/* 메소드 생략 */
2. 노드(Tokens)를 통하여 계층(Tree)구조 만들기
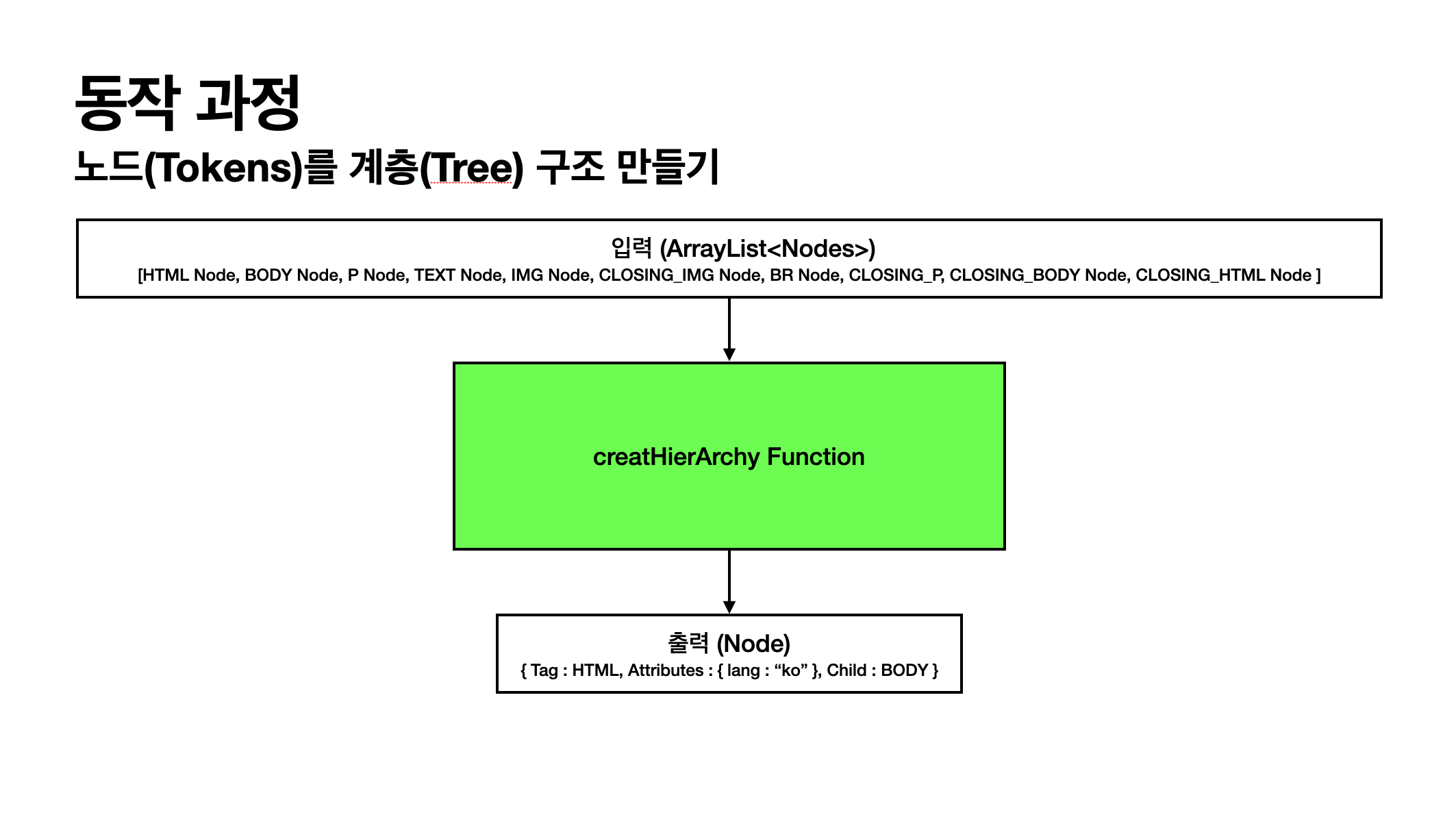
public class Lexer {
/* 필드 변수 생략 */
/* 생성자 생략 */
private Node creatHierArchy(ArrayList<Node> nodes) {
for (Node node : nodes) {
curTag = node;
if (curTag.isClosingTag()) {
while (true) {
try {
preTag = stack.pop();
} catch (EmptyStackException e) {
System.out.println("올바른 입력이 아닙니다.");
System.exit(1);
}
if (curTag.isPair(preTag)) {
break;
} else {
tempStack.push(preTag);
}
}
while (!tempStack.isEmpty()) {
preTag.addChild(tempStack.pop());
}
stack.add(preTag);
} else {
stack.push(curTag);
}
}
if (stack.size() <= 2) return stack.pop();
System.out.println("아마 잘못된 입력입니다");
return null;
}
}
계층(Tree)구조를 가지는 노드를 통해 HTML 형식으로 출력하기
public class Parser {
/* 필드 변수 생략 */
/* 생성자 생략*/
public void parseXML(Node root) {
viewer.parse(root, 0);
viewer.view();
}
}
public class Viewer {
/* 필드 변수 생략 */
/* 생성자 생략*/
public void parse(Node node, int width) {
indentation("{", width);
parseBody(node, width);
parseChild(node, width);
indentation("}", width);
}
public void parseBody(Node node, int width) {
indentation(node.getTagName(), width);
indentation(node.getAttributes(), width);
}
public void parseChild(Node node, int width) {
if(node.hasChild()) {
indentation("child : [", width);
for (Node childNode : node.getChilds()) {
parse(childNode, width + widthOffset);
}
indentation("]", width + widthOffset / 2);
}
}
public void indentation(String info, int count) {
if (info.length() == 0) return;
for (int i = 0; i < count; i++) {
sb.append(" ");
}
sb.append(info + "\n");
}
public void view() {
System.out.println(sb);
}
}
테스트 결과
public class Application {
public static void main(String[] args) {
String input = "<HTML lang=\"ko\"><BODY><P>BOOST<IMG SRC=\"codesquad.kr\"></IMG><BR/></P></BODY></HTML>";
Tokenizer tokenizer = new Tokenizer();
Lexer lexer = new Lexer();
Parser parser = new Parser();
ArrayList<String> tokens = tokenizer.tokenize(input);
Node rootNode = lexer.lexerize(tokens);
parser.parseXML(rootNode);
}
}
전체 소스코드 및 테스트 코드
https://gist.github.com/dltpwns0/daa5a02f9ece66fe01231cec3afaf702
정규표현식 학습 사이트
참고 자료
TCP School
위키피디아 - 마크업 언어
[JavaScript] DOM이란 무엇인가?
정규표현식(Regular Expression)을 소개합니다.
[JS]정규표현식(RegExp) - 이해하기 쉽게 정리 + 응용 예제
[컴파일러] 토크나이저,렉서,파서 (Tokenizer, Lexer, Parser)
'CS > 네트워크' 카테고리의 다른 글
| DNS(Domain Name System) (0) | 2022.11.29 |
|---|---|
| 웹 서버에 대해 알아가는 과정(2/2) (0) | 2022.11.29 |
| 웹 서버에 대해 알아가는 과정 (1/2) (0) | 2022.11.28 |